When Ryan Dahl created Node.js, he wasn’t driven by a desire to reinvent server-side JavaScript for the fun of it. He started from a precise technical observation: handling input/output operations with threads is a leaky abstraction. An abstraction that leaks, that lets its underlying complexity bubble up into application code, where it has no business being.
This forward-thinking mind was convinced that writing concurrent programs could be made simpler and more reliable, in particular by sparing developers the need to explicitly manage multithreading in user-land. It’s this intuition that gave rise to the Event Loop as we know it in Node.js. This first installment of the series on concurrency revisits that architectural choice and what it actually solves.
The problem: delegating threads to user-land
The historical model for handling multiple concurrent connections is clear on paper: one connection, one thread. Each incoming request is allocated its own thread of execution, which handles it from start to finish. Easy to reason about, but costly to implement once you’re after efficiency, and above all, it amounts to exposing a low-level system primitive directly in application code.
Handing thread management over to user-land quickly gives rise to a cascade of difficulties.
A fundamental complexity
Manipulating threads directly opens the door to race conditions, deadlocks, and manual management of shared resources. These aren’t implementation details: they’re entire classes of bugs, hard to reproduce and diagnose, that surface as soon as several threads of execution contend over the same state. This complexity is inherent to the model, not accidental.
A disproportionate cost
Allocating and blocking an entire thread to wait for the result of an I/O operation is a waste of resources. A thread carries non-negligible memory and scheduling costs. Tying it up entirely just to wait, most of the time, for a disk to respond or a network socket to return data amounts to over-provisioning the solution relative to the need. At scale, that’s thousands of mostly idle threads weighing on the system.
Too low a level of abstraction
A thread is a relatively low-level system primitive. In most cases, it isn’t the object you want to manipulate at the application level. Having to descend to that level just to serve requests is precisely the symptom of a leaky abstraction: the operating system’s internal machinery bubbles up into business logic.
The alternative: the Event Loop
Node.js’s proposal is to flip the responsibility. Rather than asking the developer to orchestrate threads, that orchestration is delegated to the runtime, which relies directly on the operating system’s capabilities.
It works on three building blocks:
- A main thread is dedicated to running and orchestrating the program in user-land. This is where your application code executes, in a single-threaded model that’s simple to reason about: no locks to take, no race conditions to fear in your business logic.
- This thread dispatches asynchronous tasks to the Event Loop, which takes charge of executing them and coordinating concurrency at the operating system level.
- The Event Loop relies on a thread pool to preserve the concurrent and efficient nature of the program, depending on the operating system and the nature of its APIs, which may be blocking.
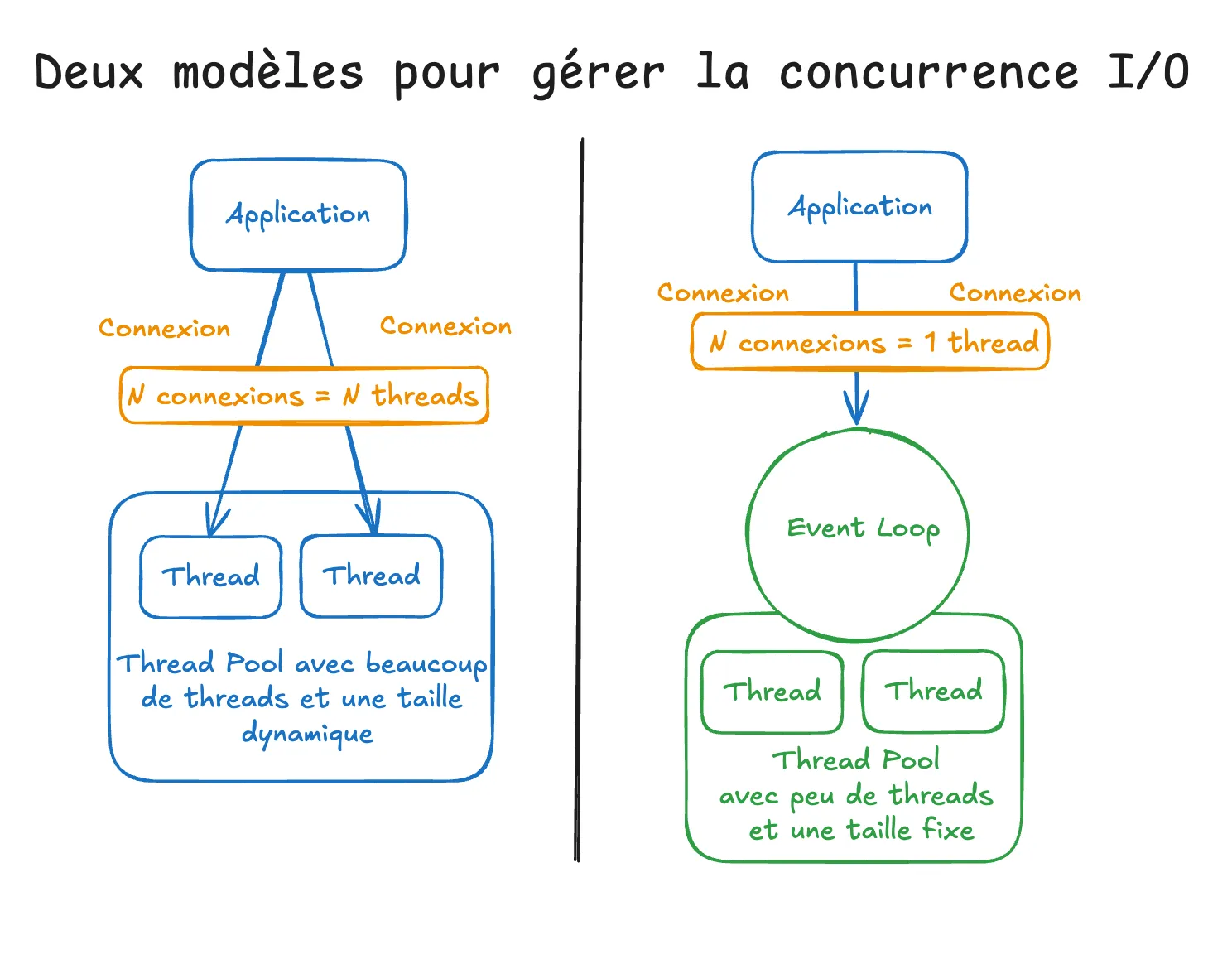
The illustration above contrasts the two models. On the left, the “one connection, one thread” model: N connections consume N threads, via a large, dynamic thread pool. On the right, the Event Loop model: N connections share a single main thread, which relies on a small, fixed-size thread pool. The difference in footprint is immediately visible.
The key idea is that this architecture moves complexity out of application code and hands it to the runtime. The runtime taps into operating system mechanisms (event notifications, non-blocking I/O) to handle concurrency efficiently without imposing that burden on the developer.
NGINX, proof at scale
This approach isn’t a Node.js peculiarity. NGINX is arguably its most emblematic example. By adopting an event-driven model rather than the traditional “one connection, one thread,” NGINX demonstrated that you could handle a very large number of concurrent connections with:
- a markedly smaller memory footprint, since you no longer pay one thread per connection;
- better performance, and notably reduced latency, since the system is no longer constrained by the scheduling cost of a multitude of threads.
It’s this validation at scale that cemented the event-driven model as a credible and durable alternative to the threaded model for heavily I/O-oriented workloads.
Toward higher-level abstractions
The underlying trend ever since has been clear: more and more platforms are adopting higher-level abstractions to express concurrency: Fibers, Coroutines, Promises, Futures, Callbacks. This is a healthy evolution: it moves the developer even further from system primitives and offers more expressive tools for describing asynchronous flows.
That said, beware of one illusion. Even with these abstractions, handling concurrency correctly remains a major challenge, far more so than most people think. A poorly composed Promise, a forgotten await, a blocking operation accidentally slipped into the main thread: abstractions hide the machinery, they don’t eliminate the pitfalls. That’s precisely the topic I dig into in the second installment of this series.
Conclusion
Ryan Dahl’s observation remains highly relevant: handling I/O with threads exposed to user-land means letting system complexity leak into code that shouldn’t have to worry about it. The Event Loop didn’t make threads disappear (they’re still there, in the runtime’s thread pool) but it put them back in their place: under the hood, managed by the runtime, as close as possible to the operating system.
Still, delegating complexity to the runtime doesn’t excuse you from understanding what’s at play. Higher-level abstractions make writing concurrent programs easier, but they don’t guarantee its correctness. That’s the whole point of what comes next: seeing why, even on top of an Event Loop, concurrency keeps resisting us.